This post describes a prototype implementation of a simple PAAS built on the Hadoop YARN framework and the key findings from the experiment. While there are some advantages to using Hadoop YARN, there is at least one unsolved issue that would be difficult to overcome at this point.
Note that this was done as part of the research works at SAP Labs!
What is HADOOP YARN?
YARN is the next generation Hadoop MapReduce architecture.
It is designed to be more flexible architecturally, improve scalability, and
achieve a higher resource utilization rate, among other things. Although YARN
remains similar to the old Hadoop MapReduce architecture (let’s call it Hadoop
MR1), the two are different enough that most components have been rewritten and
the same terminology can no longer be used for both.
In short, the Hadoop YARN architecture (or called MR2)
splits the two major functions of the JobTracker of MR1 into two separate
components – central Resource Manager and Application Master per
application. This new architecture not
only supports the old MapReduce programming model, but also opens up the possibility
of new data processing models.
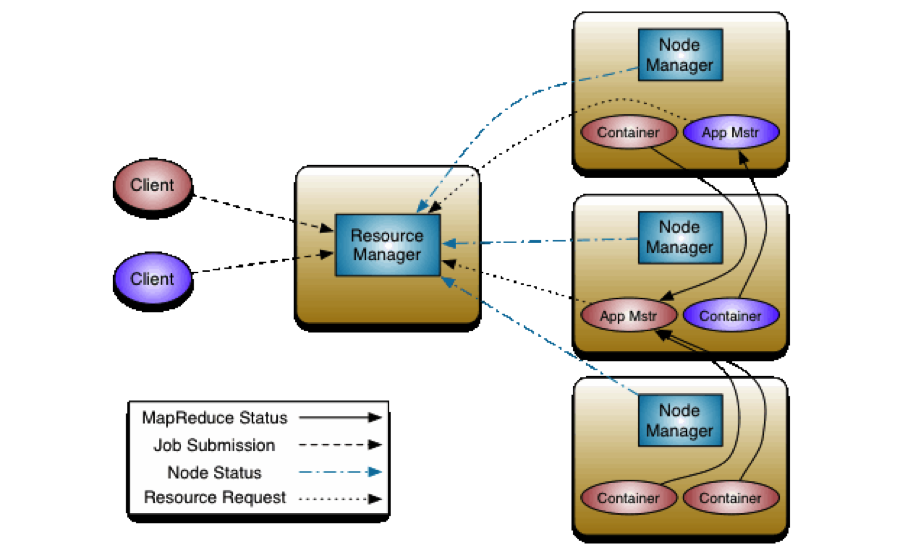 |
| Hadoop Yarn framework |
Why was HADOOP YARN considered as PAAS?
A large scale PAAS offering needs to solve many of the same
problems that Hadoop already addresses.
- Hadoop is a framework for running applications on large clusters of commodity hardware. This commodity characteristic drives down costs and avoids vendor lock in.
- Many companies have already deployed a Hadoop cluster for big data processing. So it can be easier in terms of development and operational adaptation to use it as PAAS than to adopt another PAAS solution. This can also bring in efficiency of resource utilization as one Hadoop cluster can be used for both big data processing and PAAS.
- Hadoop YARN’s three-layer architecture (client, Hadoop YARN core, application instances) looks like a good fit for PAAS.
- Hadoop YARN’s monitoring and resource management capabilities (i.e. Resource Manager and Node Managers) seem promising for PAAS.
- Hadoop is a JAVA framework, which is good for many enterprise companies in the sense that they already have enough Java developers.
- With HBase, Hadoop can be used as a NoSQL database, which can be exposed as a PAAS service.
Comparison with VMware’s Cloud Foundry
Before we jump to the prototype design and implementation,
let’s briefly take a look at a well-known PAAS, VMware’s Cloud Foundry. The
following gap analysis highlights missing components in Hadoop YARN that would
need to be added in order to create a YARN-based PaaS offering. Note that we
consider the CloudFoundry.org open source offering here, not the
CloudFoundry.com commercial offering.
 |
| VMware's Cloud Foundry |
Cloud Foundry has three distinctive architectural layers: the
client layer, the core layer, and the services and application layer. Interestingly,
this three-layer architecture is very similar to the Hadoop YARN architecture.
Client Layer
Feature
|
Cloud
Foundry
|
Hadoop
PAAS Proposal
|
Management Client
|
Has a command-line management client called ‘vmc’ to provision/update
applications, manage services, and get information about applications
|
Develop a generic YARN
client to handle commands (e.g. push, start, stop, …)
|
Application Provisioning
|
Supports WAR file
based application provisioning (e.g. vmc push myapp.war)
|
We can mimic the same push behavior in the YARN client
mentioned in the previous item, assuming that web containers (e.g. Jetty or
Tomcat) are launched and run as application containers in nodes.
|
Cloud Foundry System Layer – Core Architecture
Feature
|
Cloud
Foundry
|
Hadoop
PAAS Proposal
|
Request Routing
|
Has a Router component,
which is actually Ngnix, to route request traffic
|
There is nothing like
Router in Hadoop YARN. We need a high performance http proxy similar to
Nginx.
|
Health Management
|
Health Manager of Cloud Foundry wakes up periodically and does health checks and
does a remedy if necessary
|
In Hadoop YARN, the Application
Master in coordination with the Resource Manager can perform a similar role.
|
Messaging
|
Uses NAT as a messaging backbone among various components to
coordinate synchronization and update states
|
We need some
synchronization service among Hadoop components and non-Hadoop components
(e.g. Router). HBase uses ZooKeeper to provide similar functionality.
|
Main Controller
|
The Cloud controller of Cloud Foundry
|
The Resource Manager and
Node Managers do a similar role.
|
Droplet Execution Engines Layer – Running Services and
Applications
Feature
|
Cloud
Foundry
|
Hadoop
PAAS Proposal
|
App Running Environment
|
Droplet Execution Engine is the environment to run service and application
instances
|
A container is YARN’s shell
environment to run an application instance.
|
Java Web Container
|
Uses Tomcat as an application container in the Droplet
Execution Engine by default
|
We can use any embeddable
web container (e.g. Jetty)
|
Service support
|
Allows to
register/unregister services (MySQL, NoSQL services, and so on) and provision
applications integrated with those services
|
One of the biggest gaps
between Cloud Foundry and Hadoop YARN. No service support in Hadoop YARN.
|
Multi-tenancy
|
Supports service level Multi-tenancy. For example, the user
can provision a database service (e.g. MySQL) and bind it to his/her
application, which means that the database service instance is dedicated to
the application instances
|
Has limited support. Only
Container-level multi-tenancy is supported.
|
Hadoop PAAS Prototype
As we saw in the previous section, Hadoop YARN is missing
some PAAS components and capabilities when compared to Cloud Foundry. But it
still has many desirable features for a PAAS.
In order to better understand the characteristics of such a
system, we attempted to implement a basic PAAS prototype by leveraging built-in
functionality as much as possible and filling gaps with additional services as
needed.
Prototype Scope
The prototype was scoped to implement very basic PAAS
functionalities:
- A generic command line YARN client to provision applications, start application instances, stop a number of running application instances.
- Only Java Web applications are supported, and only WAR files as application provision packages
The
following features were not requirements of the prototype:
- Auto scaling (elasticity)
- Multi-tenancy support
- Service (relational or NoSQL database services) provision and integration
Architecture Diagram
 |
| PaaS Prototype Architecture |
- PAAS Client (PaasClient)
- PAAS Application Master (PaasAppMaster)
- PAAS Application Container (PaasAppContainer)
Beyond that, since we needed the capability of router to
serve as an entry point for incoming application requests and route requests to
the corresponding application instances, a java implementation of http proxy
called LittleProxy was slightly modified and used.
Furthermore, to synchronize the states of application
instances among PAAS components, ZooKeeper was used.
PAAS Client (PaasClient)
PaasClient is a dedicated YARN client that works like a
command shell to process PAAS commands. It’s written in Java. Users (i.e.
operators) can issue commands in the client to provision application files
(i.e. war files), start or stop application instances, get a list of instance
information, and get YARN application status.
Here are some example commands:
Command Example
|
Description
|
push
/Users/PAAS/HelloWorld.war
|
Provisions the HelloWorld application to the Hadoop
file system so that later, the PAAS Application Container can pick it up
|
start HelloWorld 2048
2
|
Starts 2 instances of the HelloWorld service with a maximum
memory limit of 2G
|
stop HelloWorld 3
|
Stops 3 instances of HelloWorld
|
instances HelloWorld
|
Returns information about
running HelloWorld instances
|
PAAS Application
Master (PaasAppMaster)
PaasAppMaster is a YARN application master that manages a
lifecycle of PAAS application instances. For each ‘start’ command, one instance
of PaasAppMaster gets created, which then tries to create the requested number
of PaasAppContainer instances. Its life lasts until all the PaasAppContainer
instances stop or fail.
PAAS Application
Container (PaasAppContainer) – Jetty Web Container
PaasAppContainer is instantiated by PaasAppMaster as a YARN
container according to the requested resource limit (e.g. memory limit of 2G).
It is a wrapper around the embedded Jetty web container that loads the war file
for the requested service (e.g. ‘start HelloWorld 2048 2’), and interacts with
Zookeeper to register and unregister itself so that the Router can update its
routing table.
Router (modified
LittleProxy)
The Router’s main function is to route and distribute
application requests to the running application instances. We used LittleProxy,
a java implementation of HTTP proxy using Netty asynchronous networking
framework, and modified it so that it maintains a routing table in ZooKeeper
and routes requests based on the routing table.
Whenever a PaasAppContainer instance registers or
unregisters to ZooKeeper, this event is notified to Router, which in turn
updates the routing table accordingly.
ZooKeeper
ZooKeeper is a centralized service to provide distributed
synchronization or maintain configurations or provide group services. Zookeeper
was used for the prototype for two main reasons:
Ø
To keep track of running application instances.
PaasAppContainer instance registers or unregisters itself to ZooKeeper when it
starts or stops. This information is used by Router.
Ø
To stop application instances in coordination with
PaasAppContainer instances as YARN does not provide a functionality to stop
individual containers.
Application War File Provisioning Flow
For simplicity, application war files are provisioned to
Hadoop file system (HDFS) so that PaasAppContainer instances can pick them up
when a ‘start’ command gets executed. This happens in the following order:
·
An Admin user issues a push command in
PaasClient like “push /Users/PAAS/svcA.war”, where svcA.war file is a web
application file of the service named ‘svcA’. Then the PaasClient uploads the
file to the Hadoop server by using ‘scp’ and ‘ssh’. There is a dedicated
directory in the Hadoop file system to save War files (e.g. /PAAS/), while
non-application libraries and jar files are stored in a different directory.
Starting-up Application Instances Flow
Assuming that all the PAAS system jar files (e.g.
PaasAppContainer and PaasAppMaster) and an application war file “svcA.war” are
already provisioned, here are the steps to start up application instances:
1.
Admin user issues a start command in PaasClient
like “start svcA 2048 3” which is to start 3 “svcA” application instances of 2G
memory limit.
2.
PaasClient connects and requests to Hadoop
Resource Manager one container for PaasAppMaster. Once it gets one allocated,
it issues a request to start PaasAppMaster in the container with some
parameters such as what application to run and how many instances to start.
3.
PaasAppMaster connects to Resource Manager again
and requests for containers for PaasAppContainer instances as many as the
requested number of instances. After it gets containers allocated, it issues
requests to start up PaasAppContainer instances for the application name “svcA”
4.
When PaasAppContainer instances get started, they
load the corresponding WAR file from Hadoop file system and starts embedded
Jetty web container. After the Jetty web container is successfully started, the
PaasAppContainer instance registers itself to ZooKeeper with the service url of
the Jetty web container.
5.
This registration event will be notified to
Router, and then Router updates its routing table. At this point, the
application instance is ready to serve app users’ requests.
 |
| Flow - Start instances |
Stopping Application Instances Flow
Because Hadoop YARN does not provide a way to stop an
individual container, the prototype uses ZooKeeper’s synchronization capability
to process stop commands:
- Admin user issues a stop command in PaasClient like “stop svcA 2” which means to stop 2 instances of svcA application.
- PaasClient chooses randomly as many instances as the requested number among the running app instances and deletes the corresponding registration information from ZooKeeper.
- These deletion (i.e. un-registration) events will be notified to the corresponding PaasAppContainer instances, and then the instances stop themselves. Although we can do a more intelligent container stopping process such as waiting for all the existing sessions to complete their works for a reasonable duration before stopping the container, we chose the simplest approach of stopping right away for the prototype. This is certainly a limit of the prototype.
 |
| Flow - Stop instances |
Testing Environment
We used Hadoop version 0.23.1. The Hadoop YARN cluster
consisted of 5 VMs. One VM was dedicated as Resource Manager, while the others
were application nodes. Router(modified
LittleProxy) and ZooKeeper were run on a separate machine.
Findings
We found certain things positive while developing the
prototype and testing with it:
- Prototype development was fast. Within a week, one person could write a basic flow including starting application instances even though he had a very limited knowledge about YARN at the beginning.
- As expected, resource management (container allocation based on a resource requirement) is done well.
- Hadoop file system is certainly good enough as an application repository.
Also, we found some negative things, too:
- The current version Hadoop YARN supports only memory-based container allocation. But we’re told that this is going to be improved in coming releases.
- There is a very limited set of monitoring APIs. For example, there is no easy way to monitor the health state of each Application container (e.g. memory consumption, and more). But again, we're told that Hadoop team is working on more monitoring capabilities now.
And there is one known issue of the prototype
implementation:
- Each ‘start’ command creates a new instance of PaasAppMaster , even though there might already be a running PaasAppMaster. This might happen, for example, when a user with a running application tries to add more PaasAppContainer instances to handle additional load. After we had implemeneted the prototype, we were told that this problem can be fixed by using YarnRPC protocol, but we didn’t try to fix it due to a development time constraint.
Conclusion
We successfully implemented a PAAS prototype whose scope is
limited to basic PAAS functionalities (i.e. provision applications, start/run/stop
multiple application instances in a random fashion in a Hadoop cluster). For
the most part, we were able to fill the gaps we identified in the beginning of
the process and built a working PAAS relatively easily and quickly. Hadoop
YARN’s memory based resource management worked very well for the PAAS
prototype.
We stopped the experiment because of a few critical
limitations would take significant work to overcome to use Hadoop YARN as a
PAAS, including Hadoop YARN’s programming model (i.e. map-reduce
or DAG programming model) and limited monitoring capabilities.
We have demonstrated that it’s already usable as PAAS for a
limited scope by adding additional components and services. Over the long term, Hadoop YARN is a promising
foundation for a PAAS, considering that the architecture is still evolving and
the above-mentioned problems may yet be addressed.
Prototype Source Code
The prototype implementation is hosted at GitHub.
But please note that it's in the middle of process to add the implementation as a Yarn example to a future release of Apache Hadoop (https://issues.apache.org/jira/browse/MAPREDUCE-4393)
View comments